到底什么是“生成式 AI”?
随着 ChatGPT、文心一言等 AI 产品的火爆,生成式 AI 已经成为了大家茶余饭后热议的话题。
可是,为什么要在 AI 前面加上“生成式”这三个字呢?
难道还有别的 AI 吗?
且听文档君慢慢道来~
1、生成式 AI 究竟是个啥?
如果将人工智能按照用途进行简单分类的话,AI 其实要被划分为两类:决策式 AI 和生成式 AI。
决策式 AI:专注于分析情况并做出决策。它通过评估多种选项和可能的结果,帮助用户或系统选择最佳的行动方案。
例如,在自动驾驶车辆中,就是通过决策式 AI 系统决定何时加速、减速或变换车道。

生成式 AI:专注于创造全新内容。它可以根据学习到的数据自动生成文本、图像、音乐等内容。
例如,你可以将几篇论文发给生成式 AI,他可以生成一篇文献综述,囊括了这几篇论文的关键思想、重要结论。

看到这里,你就知道为什么 ChatGPT、文心一言属于生成式 AI 了吧?
接下来,让我们正式走入生成式 AI 的世界。
2、生成式 AI 的前世今生
其实,生成式 AI 的并不是这几年刚刚诞生,它实际已经经历了三个阶段:
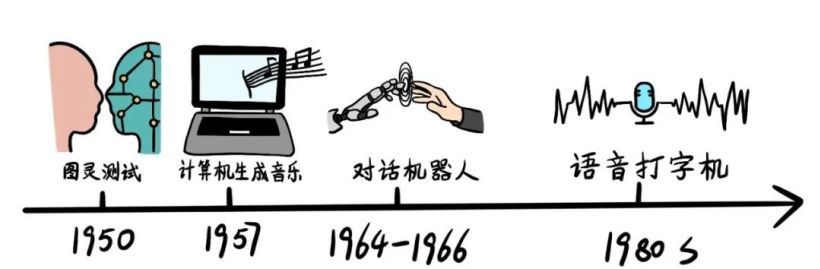
早期萌芽阶段
1950 年,Alan Turing 提出了著名的“图灵测试”,这是生成式 AI 领域的一个里程碑,预示了 AI 内容生成的可能性。
1957 年,Lejaren Hiller 和 Leonard Isaacson 完成了历史上第一首完全由计算机“作曲”的音乐作品《Illiac Suite》。
1964 年至 1966 年间,Joseph Weizenbaum 开发了世界上第一款可人机对话的机器人“Eliza”,它通过关键字扫描和重组完成交互任务。
1980 年代,IBM 公司基于隐形马尔科夫链模型,创造了语音控制打字机“Tangora”。
沉淀积累阶段
随着互联网的发展,数据规模快速膨胀,为人工智能算法提供了海量训练数据。但是由于硬件基础有限,此时的发展并不迅猛。
2007 年,纽约大学人工智能研究员 Ross Goodwin 的人工智能系统撰写了小说《1 The Road》,这是世界第一部完全由人工智能创作的小说。
2012 年,微软公司公开展示了一个全自动同声传译系统,可以自动将英文演讲者的内容通过语音识别、语言翻译、语音合成等技术生成中文语音。

快速发展阶段
2014 年起,大量深度学习方法的提出和迭代更新,标志着生成式 AI 的新时代。
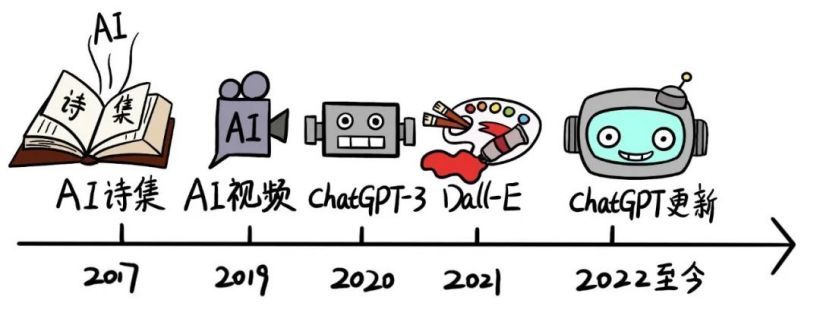
2017 年,微软人工智能少女“小冰”推出了世界首部 100% 由人工智能创作的诗集《阳光失了玻璃窗》。
2019 年,谷歌 DeepMind 团队发布了 DVD-GAN 架构用以生成连续视频。
2020 年,OpenAI 发布 ChatGPT3,标志着自然语言处理(NLP)和 AIGC 领域的一个重要里程碑。
2021 年,OpenAI 推出了 DALL-E,主要应用于文本与图像的交互生成内容。
自 2022 年开始到现在,OpenAI 多次发布 ChatGPT 新型号,掀起了 AIGC 又一轮的高潮,它能够理解和生成自然语言,与人类进行复杂的对话。
自此,生成式 AI 已经到了一个井喷式状态。那么,生成式 AI 究竟是基于什么样的原理呢?
3、轻松搞懂“生成式 AI”原理
在刚刚的介绍中,大家应该都对生成式 AI 有了一个表象的认知:学习知识 + 生成新知识。
但它是如何学习的呢?又是如何生成的呢?
这时候,我们就得来看看生成式 AI 更深层次的定义了:
定义
以 ChatGPT 为代表的生成式 AI,是对已有的数据和知识进行向量化的归纳,总结出数据的联合概率。从而在生成内容时,根据用户需求,结合关联字词的概率,生成新的内容。
是不是一下子懵了?
不急,这就触及到生成式 AI 的原理了。待文档君给你慢慢解析。
其实制作一个生成式 AI,就像把一个泥人变成天才,一共需要四步:捏泥人 → 装大脑 → 喂知识 → 有产出。

Step1:捏泥人 —— 硬件架构的搭建
要打造一个生成式 AI 的“泥人”,首先要考虑的就是底层硬件。底层硬件构成了生成式 AI 的算力和存力。
算力 —— 泥人的骨架
生成式 AI 需要进行大量的计算,尤其是在处理如图像和视频时。大规模计算任务离不开下面这些关键硬件:
GPU(图形处理单元):提供强大的并行计算能力。通过成千上万个小处理单元并行工作,大幅提高了计算效率。
TPU(张量处理单元):专门为加速人工智能学习而设计的硬件,能够显著加快计算速度,进一步增强了骨架的强度。

存力 —— 泥人的血液
生成式 AI 需要处理和存储大量的数据。
以 GPT-3 为例,光是训练参数就达到了 1750 亿个,训练数据达到 45TB,每天会产生 45 亿字内容。
这些数据的存放离不开下面这些硬件设施:
大容量 RAM:在训练生成式 AI 模型时,大量的中间计算结果和模型参数需要存储在内存中,大容量的 RAM 能够显著提高数据处理速度。
SSD(固态硬盘):大容量的 SSD 具有高速读取和写入能力,可以快速加载和保存数据,使泥人能够高效地存储信息。

泥人捏好了,但是现在只能是一个提线木偶,没有任何能力,所以我们就要给他装上大脑。
Step2:装大脑 —— 软件架构构建
软件架构是泥人的大脑,它决定了这个泥人将以什么样的方式对数据进行思考推理。
从仿生学的角度,人类希望 AI 能够模仿人脑的运行机制,对知识进行思考推理 —— 这就是通常所说的深度学习。

为了实现深度学习,学者们提出了大量的神经网络架构:
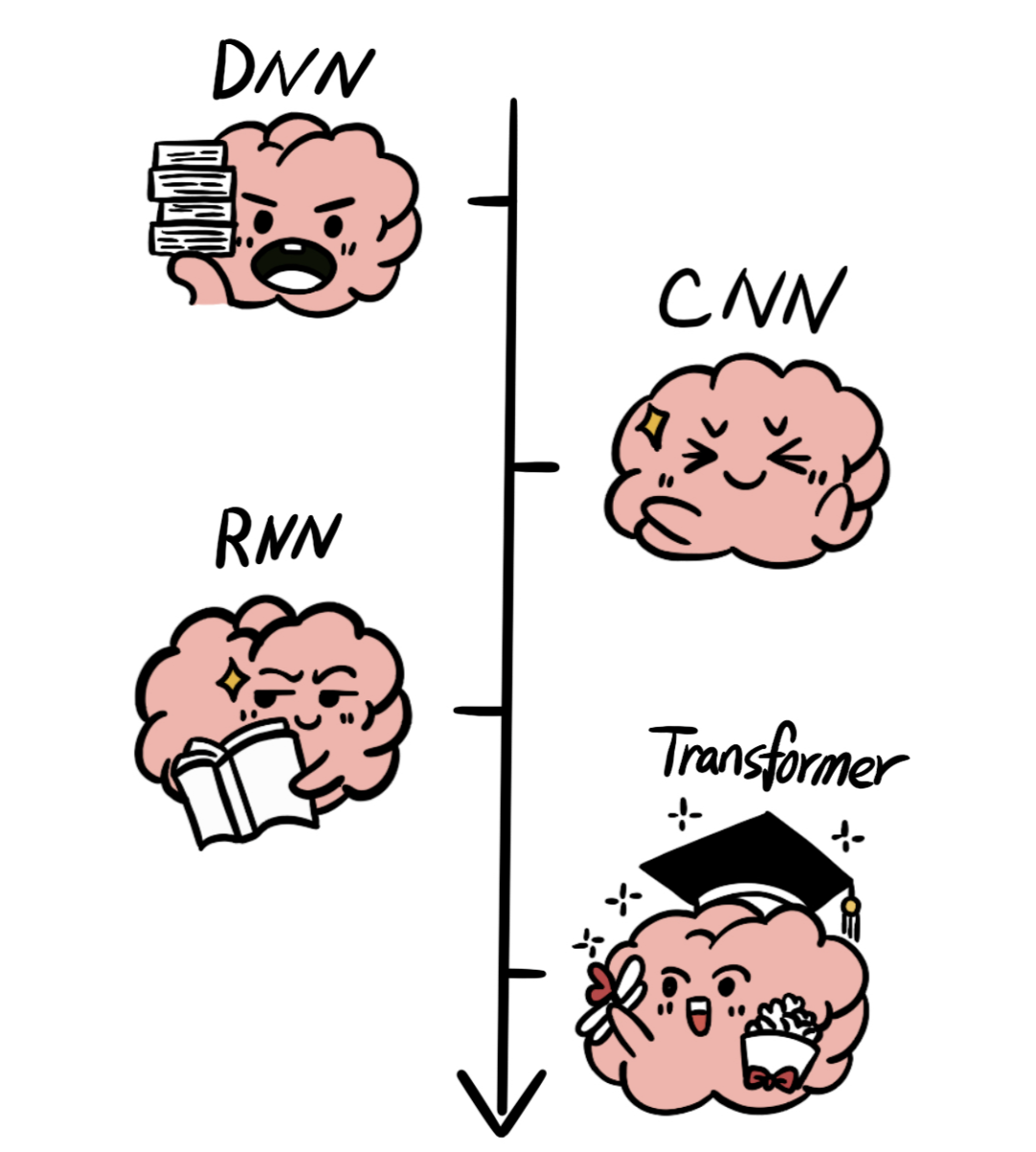
深度神经网络(DNN)是最普遍的神经网络架构,但是随着数据对于网路架构的要求越来越复杂,这种方法逐渐有些吃力。
卷积神经网络(CNN)是一种专门为处理图像数据而设计的神经网络架构,能够有效地处理图像数据,但是需要对输入数据进行复杂的预处理。
随着任务复杂度的增加,循环神经网络(RNN)架构成为处理序列数据的常用方法。
由于 RNN 在处理长序列时容易遇到梯度消失和模型退化问题,著名的 Transformer 算法被提出。
随着算力的发展,生成式 AI 的网络架构发展越来越成熟,也开始各有侧重:
Transformer 架构:是目前文本生成领域的主流架构,GPT、llama2 等 LLM(大语言模型)都是基于 Transformer 实现了卓越的性能。
GANs 架构:在图像生成、视频生成等领域有广泛应用,能够生成高质量的图像和视频内容。
Diffusion 架构:在图像生成、音频生成等领域取得了很好的效果,能够生成高质量、多样化的内容。

网络架构搭建好了,脑子是有了,但是脑子里空空如也呀。所以我们通过数据训练给这个人造大脑喂知识。
Step3:喂知识 —— 数据训练
目前有两种训练方式:预训练和 SFT(有监督微调)
预训练:是指将一个大型、通用的数据集作为知识喂给 AI 进行初步学习。
经过预训练的模型叫作“基础模型”,它对每个领域都有所了解,但是无法成为某个领域的专家。
SFT:SFT 是指在预训练之后,将一个特定任务的数据集喂给 AI,进一步训练模型。
例如,在已经预训练的语言模型基础上,用专门的医学文本来微调模型,使其更擅长处理医学相关的问答或文本生成任务。
但是,无论是预训练还是 SFT,AI 的大脑是如何吸收这些知识的呢?

这就涉及到“理解”能力了,我们以 Transformer 架构为例,讲讲 AI 对于文本的理解。
对于 AI 来说,理解分两步:理解词语和理解句子。
理解词语的本质就是词语的归类。研究人员提出了一种方法:将词语在不同维度上进行拆解,从而对词语进行归类。
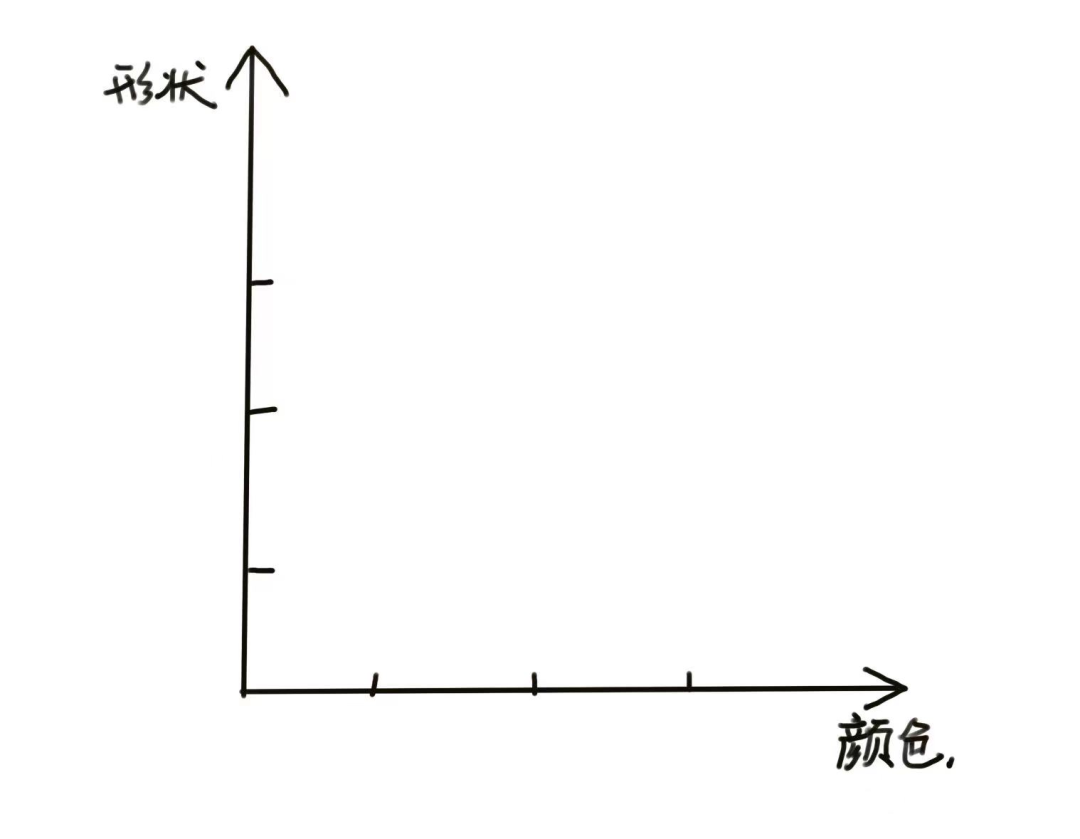
假设有四个词语:西瓜、草莓、番茄和樱桃。AI 在两个维度上对这些词语拆解:
颜色维度:用 1 代表红色,2 代表绿色。
形状维度:用 1 代表圆形,2 代表椭圆形。
基于这个维度,AI 对词语进行打分归类。
西瓜:颜色 = 2(绿色),形状 = 1(圆形)
草莓:颜色 = 1(红色),形状 = 2(椭圆形)
番茄:颜色 = 1(红色),形状 = 1(圆形)
樱桃:颜色 = 1(红色),形状 = 1(圆形)

通过这些打分,我们可以看到词语在不同维度上的分类。
例如,“番茄”和“樱桃”在颜色和形状维度上都是相同的,说明它们在这两个维度上的含义相同;“草莓”和“西瓜”在颜色和形状维度上都有所不同,说明它们在这两个维度上的含义不同。
当然,区分他们的维度不仅仅只有两个,AI 还可以从大小、甜度、是否有籽等大量维度对他们进行打分,从而分类。
只要维度足够多、打分足够准确,AI 模型就可以越精准地理解一个词语的含义。

对于目前较为先进的 AI 模型来说,通常维度的数量可以达到上千个。
学习词语并理解为量化的结果只完成了第一步,接下来 AI 就需要进一步理解一组词语的合集:句子。
我们知道即使同一个词语在不同语句中,也会具备不同的含义。
例如:
这是一顶绿色的帽子。

某某公司致力于打造绿色机房。

在不同句子中,“绿色”这个词含义不同,AI 是如何知道他们有不同的含义呢?
这就得益于 transformer 架构的“自注意力(Self Attention)”机制。
简单来说,当 AI 理解包含了一组词语的句子时,除了理解词语本身,还会“看一看”身边的词。单个词语和句子中其他词语之间的关联性,称之为“注意力”,由于是和同一个句子自身的词语结合理解,所以称之为“自注意力”。
因此,在 Transformer 架构中,可以分为以下两步:
将每个词语转换为一个向量。这个向量表示词语在多维空间中的位置,反映了词语的各种特征。
使用自注意力机制来关注句子中的不同部分。它能够在处理每个词语时,同时考虑句子中其他词语的信息。
Step4:有产出 —— 内容生成
在理解完大量词语、句子之后,AI 就可以生成内容了。它是如何生成内容的呢?
这就是一个概率的问题了。
问大家一个问题:
我在餐厅吃 ×。
× 填个字,你会填什么?
根据你既往的经验,大概率你会填“饭”。
其实,× 还可以是“饼”、“面”、“蛋”等等。
像人一样,生成式 AI 也会根据它第三步中学到的经验,给这些字加上概率。然后选择概率高的词作为生成的内容。接着,AI 将重复这一过程,选择下一个可能性最高的词语,从而生成更多内容。
但有的时候,我们希望答案是丰富多彩的,回到刚刚那个例子,我们现在不希望 AI 接的下一个字是“饭”,那要怎么办呢?
AI 提供了一个调节参数,叫温度,范围从 0 到 1。
在温度为 0 时,说明匹配概率要选尽量大的,在以上例子中,AI 很可能选择“饭”;
在温度为 1 时,说明匹配概率要选尽量小的,在以上例子中,AI 很可能选择“饼”。
数值越接近 1,得到的内容越天马行空。
比如,温度设为 0.8,那么 AI 生成的句子可能是:
我在餐厅吃饼,这个饼又大又圆,我想把它套在脖子上......

但是,我们看到大多数 AI 产品,只有一个对话框,如何修改温度参数呢?
答案是“提示词”,也就是我们通常所说的 prompt。
如果你输入是“你是一名某某领域的专家,请用严谨的口吻写一篇关于 xx 的文献综述。”这时 AI 的温度接近 0,就会选择匹配概率尽量高的词语生成句子。
如果你输入是“请你请畅想一下 xx 的未来。”这时 AI 的温度接近 1,就会选择匹配概率尽量低的词语组成句子,生成意想不到的内容。
现在知道 prompt 的重要性了吧!
所以,我们可以认为,AI 生成的本质就是一场词语接龙:AI 根据当前字,联系它之前记录的下个字的出现概率以及你的期望,选择接下来的字。

当然,生成式 AI 的内部原理远比小编讲的要复杂,小编这里只能算一个基础的科普。
4、“生成式 AI”去向何方?
那么生成式 AI 真的会实现通用人工智能,从而替代人类嘛?目前,有两种看法:
积极派:以 OpenAI 的 CEO Altman、英伟达 CEO 黄仁勋为首的积极派,非常看好生成式 AI 的未来,他们曾表示“再过几年,人工智能将会比现在更加强大和成熟;而再过十年,它定将大放异彩“,“AI 可能在 5 年内超越人类智能”。

消极派:以深度学习先驱杨立昆为首的消极派,一直认为生成式 AI 无法通向用人工智能。他在多个场合表示“像 ChatGPT 这样的大型语言模型将永远无法达到人类的智能水平”,“人类训练的人工智能,难以超越人类”。

那么对于我们普通人来说,我们要怎么对待生成式 AI 呢?
文档君觉得,我们普通人不妨就把它当做一个工具,学会使用它,提高我们的工作效率,丰富我们的日常生活,保持对世界的好奇心,充分享受科技带来的便利就好啦!
